The Inner Product, May 2004
Jonathan Blow (jon@number-none.com)
Last updated 23 July 2004
Miscellaneous Rants
As I sit down to write this article, the Game Developers
Conference is rapidly approaching. (It’ll be past by the time this column sees
print.) For me the conference tends to be a big milestone marking a yearly
cycle of game development thoughts and happenings. I always come away from the
conference with new ideas about what I ought to be doing.
This year, to prepare the way for new thoughts, I’m
attempting to flush out some of the old thoughts by getting them down on paper.
What follows is a series of short bits that I think are interesting, but which
are too small to merit their own individual columns.
Networked Game Quality-of-Service
Fast-paced networked games are sensitive to network
conditions – if you get a lot of latency or packet loss, the game can feel
unplayable. The degree of robustness amid adverse networking conditions depends
on the game’s network architecture – some systems feel much more solid than
others. Peer-to-peer lockstep games are the worst; every player is waiting for
input from every other player in order for the simulation to progress, so if any
player has poor network conditions, everyone suffers.
Client/server games can be made very robust, so that a
player’s experience depends on network quality at his client and at the server,
but not at the other clients. The server can be run from a controlled location
with effort spent to ensure that the network quality is high. So the quality of
the player’s experience depends mainly on his own connection.
When first-person shooters first became viable to play
across the Internet, they used this model. (You could place this at about the
timeframe of Quake; Doom used peer-to-peer and was painful to play
over a wide-area network). But there were lots of modem players back then, who
tended to have poor play experiences due to their slow connections (they had to
aim ahead of moving targets, would see enemies late and so have less time to
react before being killed, etc). Around the year 2000 an Unreal Tournament
mod called Zeroping was released. Zeroping aimed to improve the play experience
by allowing a lot of computation to happen client-side: you always hit what you
aim at (the server believes your client when you say you hit someone).
Of course this opens up all sorts of cheating issues, but
if you like the idea you can convince yourself that the cheats can be detected
and worked around. So this became an increasingly prevalent networking paradigm
for first-person shooters. A more sophisticated networking system, designed to
eliminate most client-side cheats while retaining lag compensation, was designed
by Yahn Bernier for Team Fortress 2 and Half-Life 2 (see the
References). It was patched into a post-release version of Half-Life as a test,
annoying untold masses of dedicated Counter-Strike players around the
world.
Yahn’s lag compensation system, and a few others since
then, involves the server interpolating objects backward in time to compensate
for clients’ latencies, in order to detect hits. So as Yahn says, “you hit what
you aim at” for instant-hit weapons (though applying his system to slower
projectile weapons is very confusing and may be infeasible, so he didn’t do it);
but at the same time the client can’t just lie about what it has hit, because
hit-detection is decided by the server.
Lag compensation systems still have significant cheating
problems (a client can lie about its latency), but even if they could be totally
solved, there are strange issues with this kind of architecture that need to be
discussed. I have been hoping for some level of insightful and rational
discussion about this subject, but such has not yet arrived. I think it’s
difficult to get a large body of people to think seriously about networking, at
least compared to something like graphics, which is a lot more visual and openly
appealing.
There are two basic issues that bother me about lag
compensation systems (with the simple Zeroping-style architectures included in
this category). For one thing, a player is no longer in control of the quality
of his game experience. A player with a perfect connection will frequently
experience low-quality events – for example, getting shot when he seems to be
safely around a corner. The worse the connection quality of the other players,
the more often this will happen.
But the thing that’s more subtle, and perhaps more
troublesome, is that the learning curve of the game changes, such that it
becomes much harder for players to understand what happened to them and thus
improve their play. In a vanilla client/server situation where you must lead
your target when lagged, you can see clearly when you hit or missed and can
learn to adjust your play accordingly. You have a clear path you can take in
order to improve. But with lag compensation, the effect of latency is to cause
you to be killed in confusing ways, wherein your client is displaying a version
of events that can be quite different from what the server considers to have
actually happened. (And in fact the server is constantly juggling conflicting
notions of the world state, so there is in fact no objective reality for you to
key in on). In such a situation, when you find yourself being killed but you
don’t have a clear picture of why it’s happening, how can you improve your
play? You can’t see what direction to go in the skill space.
Certainly this end-result is upsetting to many expert
players. But I’m not even sure it’s a good play experience for beginners.
Problems with Academic Research Pertaining to Game
Technology
Back when I was new to game programming, I looked forward
to attending conferences like SIGGRAPH because there was lots of high-end stuff
there to learn from. Nowadays, I am usually dismayed by conferences like
these. Yes, there are gems to be found in the proceedings and the sessions, but
they are small and surrounded by mud. We’re starting to see a bit of the same
thing happen at the Game Developers Conference, but I hold the academics more
strictly to task for this, because it is ostensibly the main thing they are
doing in life, so they really ought to be better at it. Here’s my laundry list
of problems with the current research environment:
- Promoting a technique as being useful for games, while
lacking an understanding of what is really appropriate for interactive
applications like games. For example, algorithms that heavily exploit frame
coherence in games should be avoided if you can help it, because they produce
feedback in the sequence of frame times, causing stuttering and ungraceful
failure modes. However, frame coherence is often the first tools that people
turn to in order to speed up an algorithm – they just do it by rote, because
that’s the way things have been done in computer graphics for decades. Most
don’t notice that these techniques were originally appropriate because they
were designed for batch applications, so no feedback loop would occur. For
us, frame coherence optimizations should be a last resort.
- Neglect of the suitability of a technique for actual
data that real people want to use (Does it work on meshes with texture
coordinates? Can you antialias the output?)
- Inappropriate cost/benefit trade-offs. All the time we
see papers proposing tremendous increases in system complexity, and
significant decreases in runtime robustness, in order to achieve some minor
performance boost. Usually we can achieve a bigger boost by ignoring such a
complicated algorithm and instead spending all that manpower hammering on a
simpler algorithm.
- Rampant salesmanship. An author is usually trying to
convince us that we should use his algorithm, when instead he should be
objectively examining its behavior. Traditionally a paper must list an
algorithm’s disadvantages, but you’ll find this section presented in a
dismissive manner; the author has written it with the goal of convincing you
that the disadvantages are unimportant. These guys call themselves computer
scientists but they are not being scientists.
- Related to the salesmanship issue, papers typically say
“Our new algorithm B is much better than traditional algorithm A, here are
performance numbers to substantiate our claim”. Because B was their pet
project, the authors worked very hard to optimize and tune it; it is almost
never the case that they put as much effort into A. The comparison is unfair
and thus isn’t worth much.
I believe the field really needs more simplifications and
unifications, rather than new complications. Every once in a while we see new
work that goes in such a direction, and that’s refreshing – but it doesn’t
happen nearly often enough.
Let’s go back for a moment to that frame coherence issue in
my first bullet point. I find this to be a subject with a lot of deep
ramifications that are rarely explored. At some level, our entire computational
architecture is based on coherence of one kind or another (memory caches and the
like). Apparently when these coherence exploitations are fine-grained enough,
they tend to average out and not cause much feedback. But still there are
exceptional cases due to pessimistic input patterns. If we wanted to get rid of
these, to make a game system that is truly real-time, we would have to throw
away much of our current computing paradigm. (This seems unlikely in the near
term!)
Another interesting issue arises at the algorithmic
high-level. Some kinds of algorithms are insensitive to the frame time.
Non-time-antialiased rendering is one of these; its runtime tends to depend only
on the scene complexity. But there are other kinds of algorithms, which we very
much need, that we don’t know how to make fast without resorting to heavy
coherence exploitation. Examples are physics and collision detection – as the
frame time increases, they want to spend more CPU, increasing frame time
further. So we use coherence in these algorithms, but in doing so we create a
situation that is somewhat unhappy.
Simple Compression
This one is not a rant!
Sometimes you want to write an integer into a file or
transmit it over the network, and you know the integer is usually going to be
small, though it could in rare cases be larger. To compress, we need an
estimate of the probability for each value. Suppose there’s a 50% chance of the
value being 0; if it’s not 0, there’s a 50% chance of it being 1 (a 25% chance
globally); if it’s not 1, there’s a 50% chance of it being 2 (a 12.5% chance
globally), and so on.
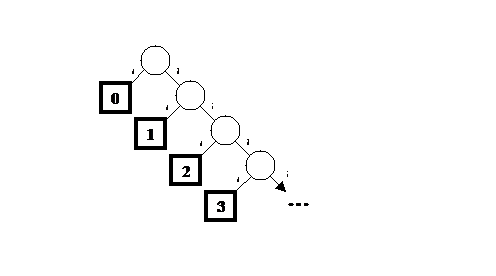
The Huffman tree for this probability distribution looks
like Figure 1. To build the Huffman codes from a tree, you just navigate from
the root to the number you want to encode, outputting a 1 for each rightward
branch and a 0 for each leftward branch. In this particular case, we see that a
0 always ends the sequence, and the number of 1s that come before that 0 is
simply the number we’re encoding.
So if your probability distribution is anywhere near this
ideal, you can get good compression on your numbers without actually
understanding compression, or doing any of the arithmetic coding stuff I’ve
talked about in the past (August – November 2003).
| |
 |
| |
Figure 1
A Huffman tree for encoding the nonnegative integers,
where 0 is the most probable value and the probability halves for each step
up the series of integers. To help keep things clear, the edges have been
labelled “l” and “r” rather than the 0 and 1 bits you might use to encode
them. To encode the number 2 using this tree, you would output rrl,
that is, 110. The ellipses indicate that the tree continues indefinitely.
|
Hexagonal Lattice Texture Maps
As I discussed in “Transmitting Vectors” (July 2002),
hexagons provide a lower-error tiling of the plane than squares do. With
texture maps, we are trying to approximate a continuous surface of color (or
some other quantity) with a lattice of samples, and usually we use a square
lattice. If we used hexagons instead, we could save memory (because we’d need
fewer samples to achieve the same amount of resolution). Furthermore, we would
increase isotropy, which can be extra important when using texture maps to
approximate pieces of functions and then multiplying them together or combining
them in some other way.
This raises interesting questions, such as what coordinate
system would be best to index the texture map. It’d be an interesting area to
experiment in, though low-level hardware support for hexagonal texture maps
seems unlikely. Nevertheless, I think one could do some wacky and fruitful
experiments by projecting slices of a 3D cubic texture map down to 2D hexagonal
maps. (See Charles Fu’s posting in For More Information).
For rendering, this is likely to fall into the general
category of “too hard to deal with to be worth the benefit”, so I’m not
recommending you go out and stick this into our engine. But when it comes to
techniques as pervasive and fundamental to what we do as texture maps, I like to
understand everything I can about the technique. If we do something
inefficiently, it should be out of choice, not ignorance.
For a use of hexagonal texture maps in computer vision, see
Lee Middleton’s paper in For More Information.
Computer Vision
The state of computer vision research can be split pretty
easily into two parts, the low level and the high level. The low level is about
looking at grids of pixels and extracting useful information from them (passing
filters over the image, using signal processing to measure texture, phase
congruency detection, the generalized Hough transform, and things like that).
The high level is about taking that low-level information and doing some AI to
parse the image (recognize shapes in the scene, detect faces, or whatever).
In general the low-level research is well-founded. Those
guys know what they’re doing, and their work is based on solid concepts.
Sometimes when I read a good low-level computer vision paper, I feel like it was
written by the Terminator. On the other hand, high-level vision papers always
seem like they were written in crayon. The concepts involved are obviously
total hacks, which clearly won’t work in the general case, or lead to any kind
of substantial high-level vision paradigm. To date, the best high-level vision
research doesn’t seem to be anything you wouldn’t think of yourself if you sat
down for a weekend and sketched out some ideas. But the high-level papers seem
to take themselves very seriously, for some reason.
References
Yahn Bernier, “Lag Compensation”,
http://www.gdconf.com/archives/2001/bernier.doc
Lee Middleton, “Markov Random Fields for Square and
Hexagonal Texture Maps”,
http://www.ecs.soton.ac.uk/~ljm/archive/c_middleton2002mrf.pdf
Charles Fu, “Which point is in the hex?”, post to
rec.games.programmer, June 1994. Message-ID <2sqchi$a1j@gap.cco.caltech.edu>.
Zeroping home page,
http://zeroping.home.att.net